
🧑🏫 Instruction Tuning Vol. 1
The most popular instruction datasets

NLP and ML have gone through several phases of how models are trained in recent years. With the arrival of pre-trained models such as BERT, fine-tuning pre-trained models for downstream tasks became the norm. The increasing capabilities of ever larger models then enabled in-context learning via prompting. Recently, instruction tuning has become the newest method to make LLMs useful in practice.
In this edition, we will cover some of the most popular datasets for instruction tuning. The next editions will cover the latest instruction datasets and instruction-tuned models.
What is Instruction Tuning?
The main difference between instruction tuning and standard supervised fine-tuning lies in the data that the model is trained on. Whereas supervised fine-tuning trains models on input examples and their corresponding outputs, instruction tuning augments input-output examples with instructions, which enables instruction-tuned models to generalize more easily to new tasks.

Methods differ based on how the instruction tuning data is constructed. Zhang et al. (2023) provide a good overview of existing instruction datasets. Existing datasets fall roughly into two main categories: a) instructions are added to existing NLP tasks; and b) data from (a) is used to condition a model to generate new instruction-input-output tuples. Let’s now look at some of the most popular instruction datasets:
Natural Instructions (Mishra et al., 2022): 193k instruction-output examples sourced from 61 existing English NLP tasks. Crowd-sourcing instructions from each dataset are aligned to a common schema. Instructions are thus more structured compared to other datasets. Outputs are relatively short, however, which makes the data less useful for generating long-form content.

Two instances of Natural Instructions. The instruction schema covers multiple fields including a definition, things to avoid, and positive and negative examples. Natural Instructions v2 / Super-Natural Instructions (Wang et al., 2022): A crowd-sourced collection of instruction data based on existing NLP tasks and simple synthetic tasks. It includes 5M examples across 76 tasks in 55 languages. Compared to Natural Instructions, instructions are simplified; they consist of a task definition and positive and negative examples with explanations.

An instance of Super-Natural Instructions. Instructions consist of a task definition and positive and negative examples with an explanation. Unnatural Instructions (Honovich et al., 2023): An automatically collected instruction dataset of 240k examples where InstructGPT (text-davinci-002) is prompted with three Super-Natural Instructions examples—consisting of an instruction, input, possible output constraints—and asked to generate a new example. The output is generated separately by conditioning on the generated instruction, input, and constraints. The generated instructions are then further paraphrased by prompting the model. Unnatural Instructions covers a more diverse set of tasks than Super-Natural Instructions; while many examples reflect classical NLP tasks, it also includes examples of other interesting tasks.
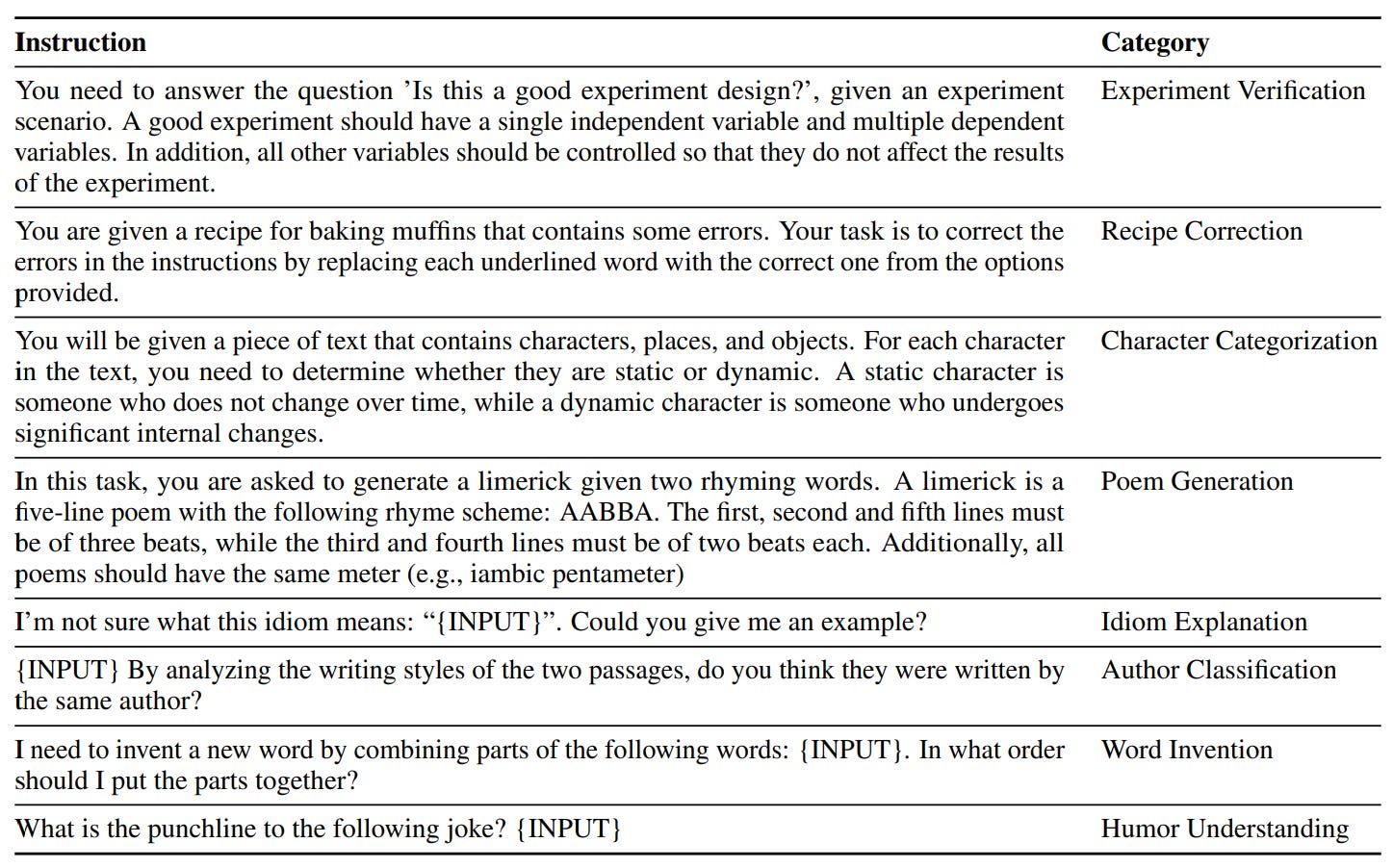
Examples of eight interesting generated instructions that differ from classical NLP tasks in Unnatural Instructions. Self-Instruct (Wang et al., 2023): Similar to Unnatural Instructions, Self-Instruct consists of 82k examples automatically generated using InstructGPT conditioned on a set of seed task examples (175 tasks in total; one example per task; 8 examples are sampled for in-context learning). Self-Instruct decouples the example generation by first generating the instruction, then the input (conditioned on instruction), and then the output. For classification tasks, the authors first generate the possible output labels and then condition the input generation on each class label to avoid biasing towards a specific label. While the generated instructions are mostly valid, the generated outputs are often noisy.

Examples of generated instruction-input-output tuples in Self-Instruct. P3 (Public Pool of Prompts; Sanh et al., 2022): A crowd-sourced collection of prompts for 177 English NLP tasks. For each dataset, about 11 different prompts are available on average, which enables studying the impact of different prompt formulations. Compared to the instructions in the above instruction datasets, P3 prompts are often shorter and less elaborate.
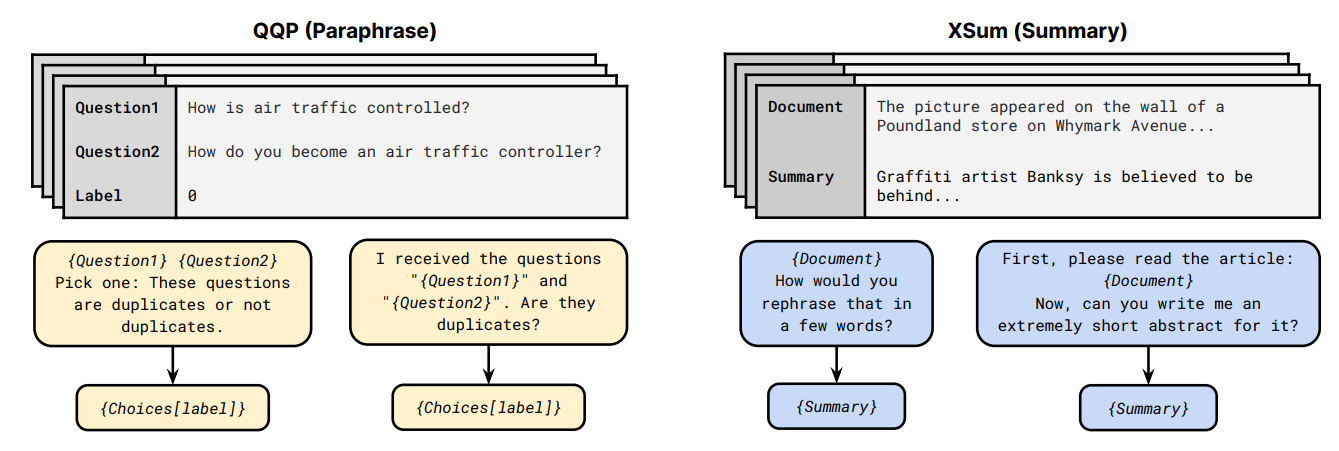
P3 prompt templates for two existing NLP tasks. Prompt templates use fields of the raw data (e.g., {Document}) and template metadata (e.g., {Choices[label]}). xP3, xP3mt (Muennighoff et al., 2023): An extension of P3 including 19 multilingual datasets and 11 code datasets, with English prompts. They also release a machine-translated version of the data (xP3mt), which contains prompts automatically translated into 20 languages. Fine-tuning on multilingual tasks with English prompts further improves performance beyond only fine-tuning on English instruction data.

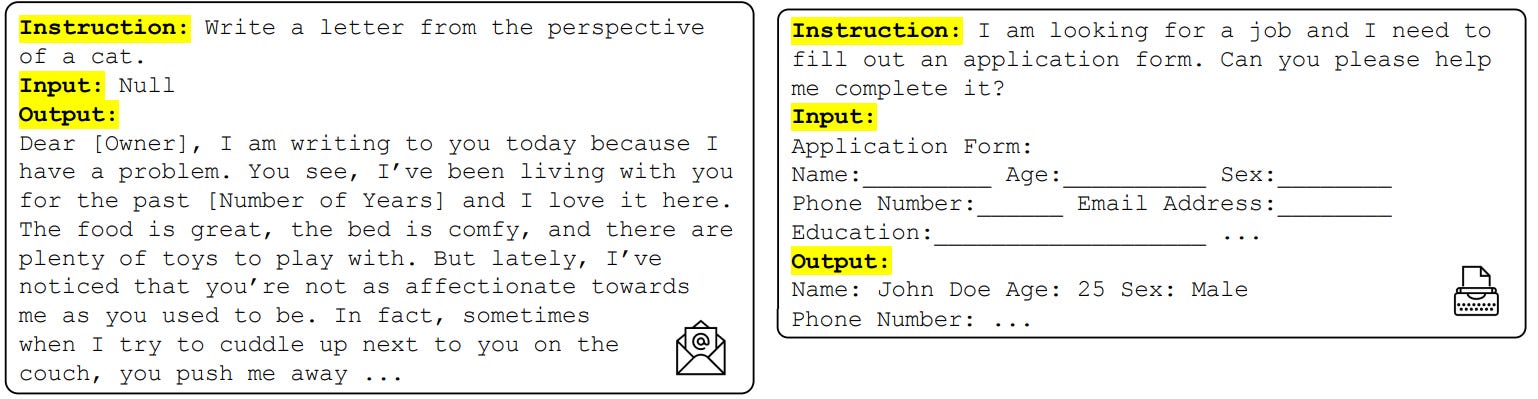
Prompt templates in P3, xP3, and xP3mt. Prompts are in English in P3 and xP3. Flan 2021 / Muffin (Wei et al., 2022): Prompts for 62 English text datasets, with 10 prompt templates for each task. For classification tasks, an
OPTIONSsuffix is appended to the input in order to indicate output constraints.
Instructions, inputs, and outputs for three tasks in Flan 2021. Flan 2022 (Chung et al., 2022): A combination of Flan 2021, P3, Super-Natural Instructions, and additional reasoning, dialog, and program synthesis datasets. The 9 new reasoning datasets are additionally annotated with chain-of-thought (CoT; Wei et al., 2022) annotations.

Flan 2022 instructions enable fine-tuning with and without exemplars (few-shot vs zero-shot) and with and without chain-of-thought. Opt-IML Bench (Iyer et al., 2022): A combination of Super-Natural Instructions, P3, and Flan 2021. They additionally include dataset collections on cross-task transfer, knowledge grounding, dialogue, and a larger number of chain-of-thought datasets.

Different prompt formulations of the COPA task in Opt-IML Bench.








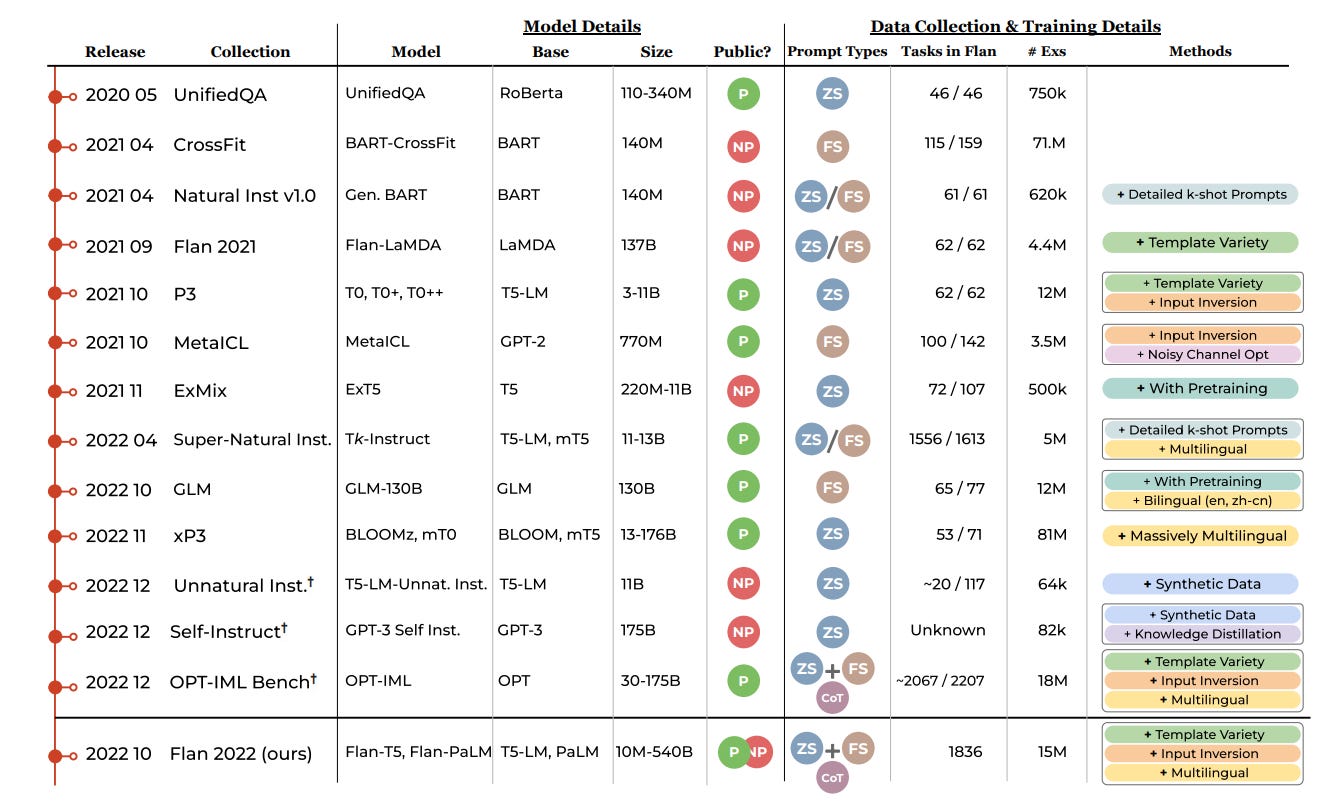
Longpre et al. (2023) provide a nice overview of the timeline of some of the above datasets as well as some of their core attributes:
Important Aspects of Instruction Data
Longpre et al. (2023) and Iyer et al. (2022) ablate several important aspects of instruction data, which we highlight in the following.
Mixing few-shot settings. Training with mixed zero-shot and few-shot prompts significantly improves performance in both settings.
Task diversity. Large models benefit from continuously increasing the number of tasks.
Data augmentation. Augmenting the data such as by inverting inputs and outputs (e.g., turning a question answering task into a question generation task) is beneficial.
Mixing weights. When using a combination of instruction tuning datasets, appropriately tuning the mixing weights is important.
While the above datasets are mainly derived from classical NLP tasks, recent datasets such as Baize (Xu et al., 2023), OpenAssistant Conversations (Köpf et al., 2023) and others cover a more diverse set of applications and domains. We will discuss these in the next edition. Stay tuned! 👋