
Command R+
The Top Open-Weights LLM + RAG and Multilingual Support

This post is an update on what I’ve been up to since I joined Cohere. I’ve had fun contributing to the launch of Command R and R+, the latest Cohere models. I’ll discuss more details once the tech report is out; in the meantime I’ll share what I’m most excited about.
Command R+ is ranked as the top open-weights model on Chatbot Arena, even outperforming some versions of GPT-4. Why is this exciting?
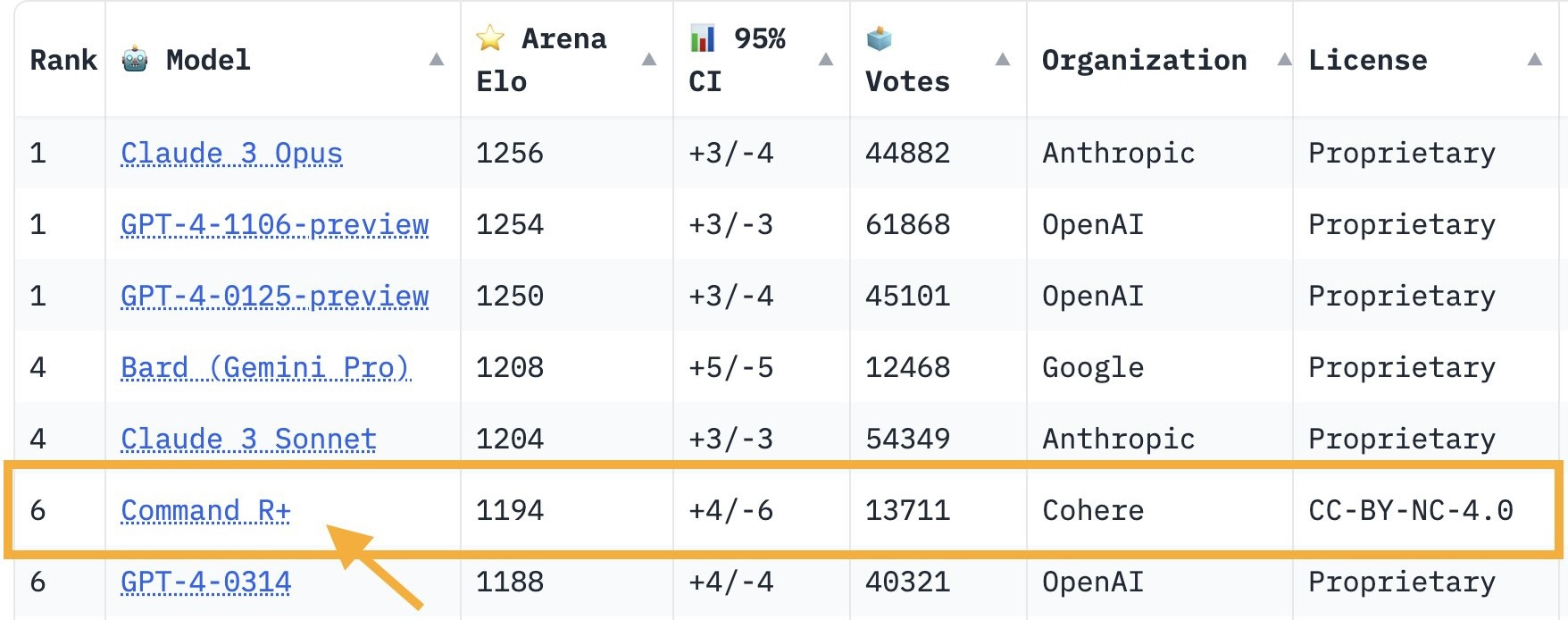
Chatbot Arena
Let’s talk about why we should care about Chatbot Arena rankings in the first place. I’ve written in the past about challenges in NLP benchmarking. Pre-LLM benchmarks such as SuperGLUE mostly consist of classification tasks and no longer provide sufficient signal to differentiate the latest generation of LLMs. More recent benchmarks such as MT-Bench consist of small samples of open-ended questions and rely on LLMs as evaluators, which have their own sets of biases.1
MMLU, one of the most widely used benchmarks consisting of 14k multiple-choice questions sourced from public sources covering 57 domains has been featured prominently in GPT-4, Claude 3, and Mistral Large posts. The data is not without errors, however, and given its release in 2020, training data of recent models is likely at least partially contaminated.
Chatbot Arena is a platform where users rate conversations in a blind A/B test. They can continue the conversation until they choose a winner. Of course, short user interactions often do not reveal more advanced model capabilities and annotators can be fooled by authoritative but non-factual answers. Nevertheless, this is the closest to an assessment on realistic user interactions that we currently have. As models are always evaluated based on new user conversations, there is no risk of data contamination.
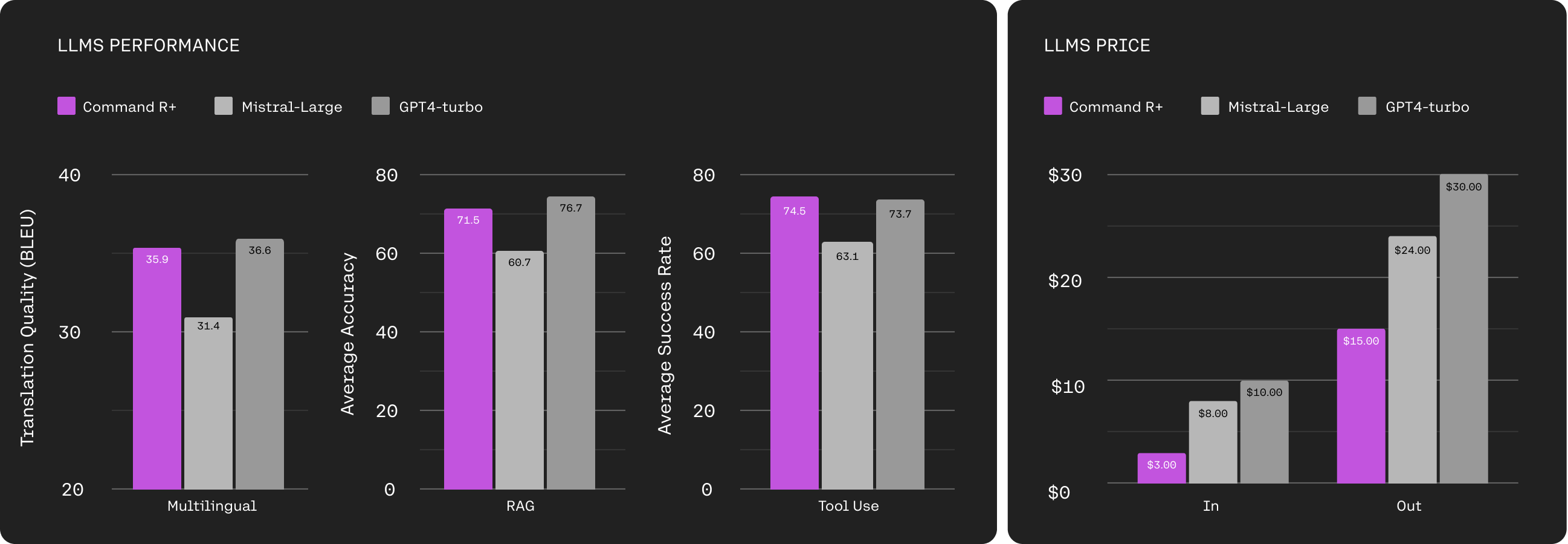
Command R+ outperforms versions of GPT-4 on Chatbot Arena while being much cheaper to use. It does also well on use cases that are under-represented in Chatbot Arena such as RAG, tool use, and multilinguality.2
A GPT-4 Level Model on Your Computer
Command R+ consists of 104B parameters with publicly available weights. This is the first time that a model that is close to GPT-4 performance is available for research use. With the right setup, Command R+ can generate text at a rate of 111 tokens/s (!) when deployed locally.3 To understand how to effectively prompt the model, check out the prompting guide.
I’m excited about what this means for the open-source community and research, with the gap between closed-source and open-weight models closing and SOTA-level conversational models being more easily accessible.
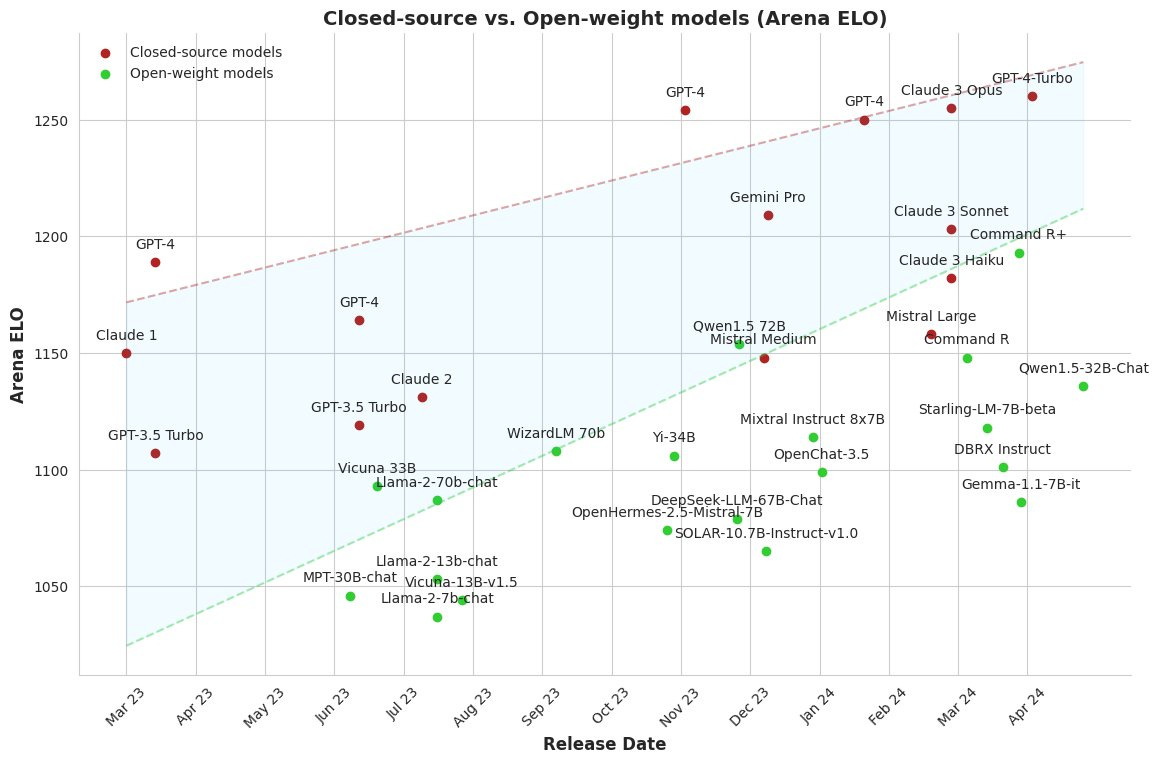
Other recently released models such as DBRX (132B parameters), Mixtral 8x22B (176B parameters), and Grok-1 (314B parameters) are based on a Mixture-of-Experts (MoE), trading off inference speed for memory costs. While these models only activate a subset of parameters for each token, they still require storing all parameters in-memory, which makes them harder to use locally. So far, they are not available or rank much lower than Command R+ on Chatbot Arena.4
Command R+ comes with a non-commercial license. If you want to self-host or fine-tune it for commercial purposes, we’ll work with you to find something that works for you.
RAG and Tool Use
While Command R+ can be used as a chatbot, it has been designed for enterprise use. Faithful and verifiable responses are especially important in an enterprise setting. Reducing hallucinations and providing trustworthy responses are important research challenges. There are different ways to mitigate hallucinations, ranging from debiasing and model editing to specialized decoding strategies (see Huang et al. (2023) for an overview).
Retrieval-augmented generation (RAG; Lewis et al., 2020), which conditions on the LLM’s generation on retrieved documents is the most practical paradigm IMO. Command R+ uses RAG with in-line citations to provide grounded responses.
However, evaluation of the quality and trustworthiness of such responses is challenging and motivated the development of new evaluation frameworks such as Attributable to Identified Sources (AIS; Rashkin et al., 2023).5 On our internal human evaluation measuring citation fidelity, Command R+ outperforms GPT4-turbo. On public multi-hop QA benchmarks, it outperforms models at the same price point such as Claude 3 Sonnet and Mistral-large.6

You can easily use RAG via the API on the Internet or your own documents. A complete RAG workflow additionally involves document search and reranking, which can be seen in this Colab with an example RAG setup on Wikipedia.

In enterprise settings, seamless integrations with existing APIs and services is crucial. I’ve written before about the promise of tool-augmented models. Tools can help decompose complex problems and make LLMs outputs more interpretable by enabling users to look at the trace of API calls. Command R+ has been trained for zero-shot multi-step tool use. On public tool use benchmarks, it outperforms GPT4-turbo.

The recommended way to leverage multi-step tool use with Command R+ is via LangChain. To teach the model to use a new tool, you only need to provide the name, definition (a Python function), and the arguments schema. The model can then be used as a ReAct agent in LangChain with a range of tools (see this Colab for an example workflow).

I hope that strong support for RAG and tool use in an open-weights model will lead to progress in important research directions, some of which I have outlined here. If you want the most efficient solution for RAG, Command R demonstrates highly competitive RAG and tool-use performance at cheaper cost (35B-parameter weights are publicly available).
Multilingual
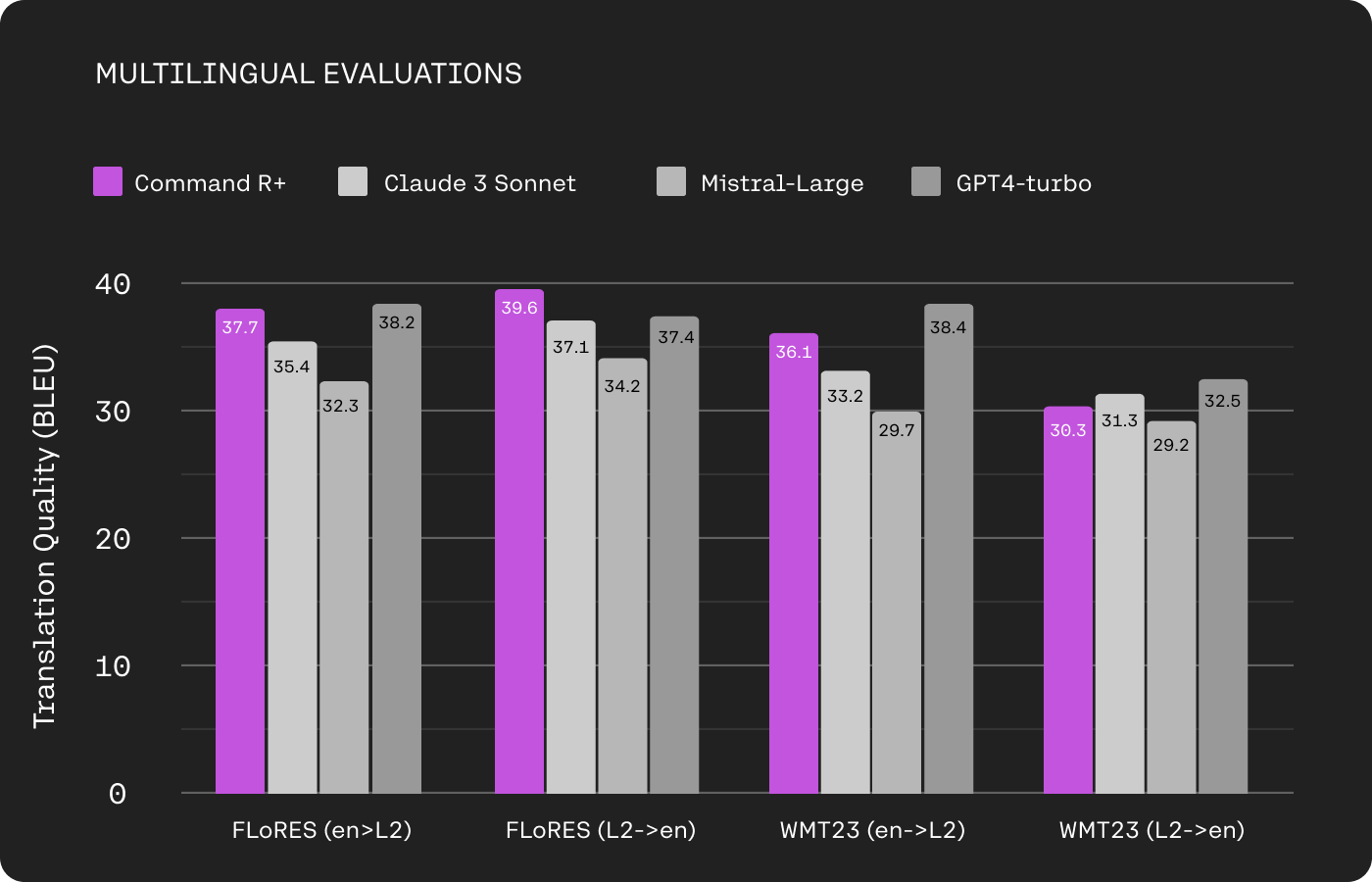
Command R+ works well in languages beyond English. It was pre-trained on 23 languages, with our main focus on 10 key language of global business: English, French, Spanish, Italian, German, Brazilian Portuguese, Japanese, Korean, Simplified Chinese, and Arabic. In our evaluations on translation tasks, it is competitive with GPT4-turbo.
Command R+ has been designed with multilinguality in mind. Its tokenizer is much less English-centric than others and compresses text in non-English languages much better than both the Mistral and OpenAI tokenizers.7 As LLM providers charge based on the number of input/output tokens, tokenizer choice directly impacts API costs for users. At the same cost-per-token, if one LLM generates 2x as many tokens as another, the API costs will also be twice as large.

Ahia et al. (2023) highlighted that such over-segmentation leads to “double unfairness”: higher API prices and lower utility (reduced performance) for many languages. In comparison, Command R+ is much more equitable. I hope that companies will take into account the impact of tokenization and other design choices on API costs in future LLMs.
Given the focus on the Latin script in existing models, I particularly want to highlight Command R+’s performance in some prominent non-Latin script languages: Japanese, Korean, and Chinese. We evaluated on translation tasks as well as language-specific benchmarks such as Japanese MT-Bench8. Command R+ outperforms Claude 3 Sonnet and Mistral Large9 and is competitive with GPT 4-Turbo.
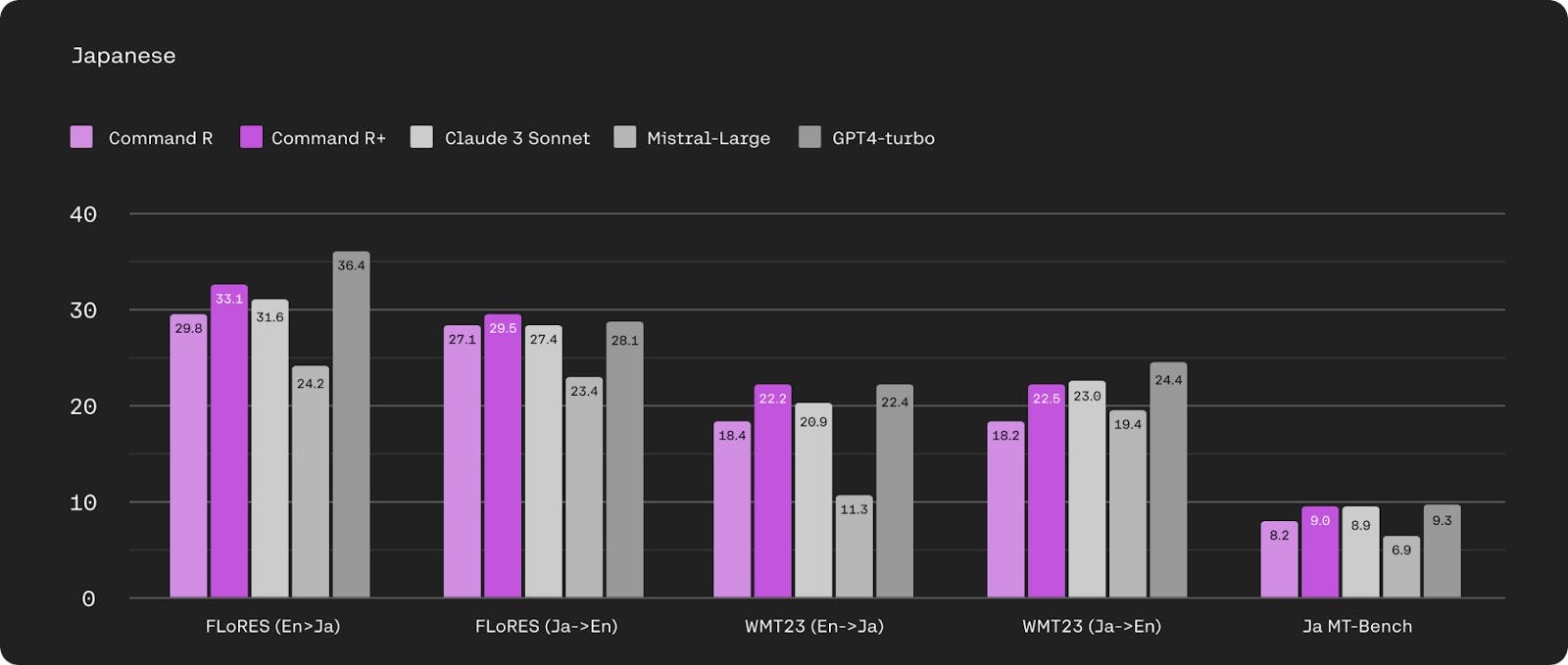
We see similar trends for evaluations in Korean and Chinese. On Chinese Chatbot Arena, Command R+ is only behind GPT4 and Claude 3 Opus, models that are 2–3x more expensive. It’s been exciting to read the feedback from speakers of different language communities using Command R+.
Conclusion
Overall, I’m really excited about Command R+’s capabilities and the future of LLMs. We will be pushing its multilingual capabilities to make it useful in many languages used in business. I’ve been using Command R+ with RAG via Cohere’s playground for my exploratory Internet searches and creative tasks in English and German and have been impressed by its quality. Feel free to try it in your language—and share your feedback in the comments or via email. I’d love to hear what works or doesn’t work for you.
I’m also excited to hear from you if you’d like to explore using Command R+ for your (multilingual) business applications.
LLM evaluators prefer longer responses or are affected by the order in which responses are presented.
This is on 4x A100 GPUs using a highly optimized open-source backend. Quantized versions of Command R+ can be run on 2x 3090 GPUs at around 10 tokens/s.
DBRX ranks at #26 on Chatbot Arena as of the publication date of this post.
Things used to be easier when the default setting was purely extractive QA and accuracy and exact match (EM) were the go-to metrics (see, for instance, Natural Questions or TyDi QA). With generative models, automatically identifying whether a (possibly verbose) response answers a question is much more challenging.
Evaluation for HotpotQA and Bamboogle is done via a committee-of-LLMs-as-judges to reduce evaluator bias.
The Anthropic tokenizer is not public so we could not compare to them.
We use GPT4 as an evaluator so this evaluation is biased towards GPT4-turbo.
Mistral Large doesn’t officially support these languages so its results are expectedly lower.
Note that if you pass a prompt to Anthropic’s API, the header should return your prompt tokens used, which can be used to do comparisons across different language datasets