
✨ Flashier Attention, 🤐 Gzip Classifiers

Hi all,
This newsletter has been on hiatus for some time due to some personal developments (I became a father recently 👶). So besides tackling an avalanche of dirty nappies, I’ll also wade again through the sea of arXiv research papers.
As before, in each edition, I will analzye a couple of topics (each consisting of one or multiple papers) by contextualizing them and reflecting on what they entail for the future of NLP and large language models (LLMs).
Note: If you enjoy synthesizing information and connecting your work to the broader research manifold, then you might also be interested in The Big Picture Workshop, which I’m co-organizing at EMNLP 2023 (submission deadline: September 1).
✨ Flashier Attention: Towards long-range models via hardware optimization
The current generation of large language models is based on the Transformer architecture. One of the limitations of Transformers is that the time and memory complexity of self-attention, one of its core building blocks, is quadratic in the sequence length. This makes scaling to very long sequences such as books, many documents, or rich interaction data prohibitive.
Numerous efficient attention methods have been proposed over the years (see this survey for an overview). Most of these methods seek to reduce the number of operations by approximating the attention algorithm, for instance, by sparsifying the attention matrix. However, the theoretical efficiency gains of these methods rarely translate into practical speed-ups as sparse-matrix operations are still poorly supported by current accelerators.

FlashAttention (arXiv May ‘22) is a method that takes into account the hardware constraints of attention and reduces the number of times the slow GPU memory needs to be accessed during the attention computation. Specifically, it a) computes the softmax incrementally and b) stores the softmax normalization factor for faster recomputation in the backward pass. For a more detailed explanation, check out this article by Aleksa Gordić.
FlashAttention achieves speed-ups between 2–3x for different Transformer models and has enabled scaling Transformers to longer sequence lengths. It is the first method that achieved non-random performance on the challenging Path-X task of Long-Range Arena, a benchmark for assessing efficient Transformers. It is now available as a plug-in replacement for attention in many ML frameworks.
Recently, Tri Dao, the first author of FlashAttention, proposed FlashAttention-2 (arXiv July ‘23), which offers additional hardware optimizations by a) reducing the number of FLOPs; b) parallelizing not only over batch size and number of heads but also over sequence length; and c) further partitioning operations within each thread.
The second optimization in particular enables scaling to very long sequence lengths (as Trio Dao explains in this blog post). Methods like FlashAttention-2 that make modeling of long sequences feasible have several implications for LLMs and efficient Transformers:
Models will be able to use much longer inputs. This lifts restrictions on users and developers. For instance, developers no longer need to artificially split or truncate long documents or come up with elaborate ways to reconcile model outputs from different subsets of the input.
Existing applications will get revisited and updated. Many existing NLP applications such as multi-document summarization and open-domain question answering have been subject to input length restrictions. New benchmarks and methods will reframe these tasks in light of long-context modeling.
Long-sequence modeling enables new applications and research directions. Modeling of extremely long sequences such as entire books, rich user interaction, and other forms of longitudinal sequential data is now possible. Credit assignment over such long sequences is still a challenge, however, as well as understanding and optimizing long-range memory (see, e.g., Rae & Razavi, 2020). Long-range sequence modeling may also be a boon for more granular representations such as character-level models (Clark et al., 2022; Tay et al., 2022), which have been hindered by limits on sequence length.
Hardware constraints will play a bigger role in influencing future advances. This has been the case throughout the history of ML but will become more pronounced in light of the huge compute budgets necessary to train current models. We will see more methods that achieve gains in efficiency through clever hardware utilization; some recent examples: TinyTL (memory reduction by only updating biases), LoRA (adapters without additional inference latency), and QLoRA (quantized adapters).
🤐 Gzip: The case for simple models
In light of the excitement around pre-trained Transformer models, it may be easy to forget that there are a huge range of other architectures and models, which may be more suitable depending on what considerations are important for a given use case.
I am generally a fan of papers that diverge from the beaten track and explore or revisit under-explored methods. During my PhD, for instance, I explored classic semi-supervised learning methods (ACL 2018). Another paper in this vein that I enjoyed is by Tay et al. (ACL 2021) who compared pre-trained convolutions to pre-trained Transformers.
Recently, another contrarian paper attracted attention on Twitter. It proposes using a gzip-based compression and distance metric with a k-nearest-neighbor classifier for text classification (Findings of ACL 2023).1 Remarkably, the authors show competitive performance with more complex non-pre-trained methods on six text classification datasets and even seemingly outperform BERT on five out-of-distribution datasets.
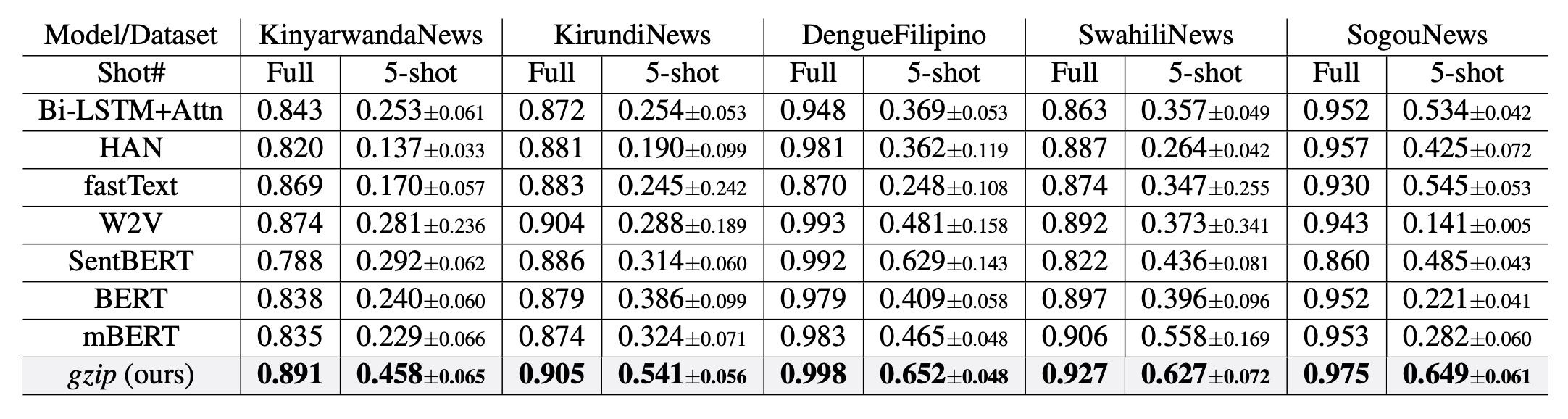
The authors set a good example by releasing the source code of their method, enabling others to experiment and to try to reproduce their results. However, researchers such as Ken Schutte quickly identified some inconsistencies with their method. Specifically, the authors report an ‘oracle’ top-2 accuracy for their method rather than a standard accuracy as used by the baselines; in addition, there are issues with the underlying source datasets, which lead to unreliable results while computing the distance metric for large training sets is excessively slow. Juri Opitz also observes that a bag-of-words-based distance metric outperforms gzip-based distance.2
Unfortunately, as usual, there is ‘no free lunch’ in machine learning—at least when it comes to non-pre-trained models. It is unlikely that a simple method such as gzip-based compression outperforms pre-trained models that have learned much richer representations unless it has been designed with specific use cases in mind.
Nevertheless, simplicity is a virtue. The promise of simple models is interpretability, which has proven elusive in the current era of black-box behemoths. Two of my favorite ‘classic’ examples of deceptively simple methods that punch above their weight are the Deep Averaging Network (ACL 2015) and the feature-based classifier used to examine the CNN/Daily Mail dataset (ACL 2016). The latter demonstrates the advantage of interpretability, highlighting that simple features are sufficient for many reading comprehension questions.
A family of models that expertly embodies this notion of simplicity and interpretability are Generalized Additive Models (GAMs)3, which consist of a linear combination of single-feature functions:
where g is the ‘link’ function such as a logistic function. Recently, Neural Additive Models (NAMs; NeurIPS 2021), a neural extension of GAMs have been proposed, which learn a linear combination of single-feature neural networks. We have not seen much of these models in practice for NLP applications due to the high dimensionality of language features and the complexity of natural language.

Nevertheless, as we continue to design models that are most useful to real-world users, it is important to remember that huge pre-trained models may not be the silver bullet for every problem. We should be aware that there are glass-box models that are more interpretable and efficient and may thus be a better fit for applications where these characteristics are important.
How to optimally compress text is a long-standing problem. The Hutter Prize, for instance, asks participants to compress enwik9 as much as possible. Abhinav Upadhyay compares alternative compression algorithms to gzip in this post.
It is important to remind ourselves that this follow-up work was mainly possible because the authors released their code—kudos to them!
Generalized linear models such as logistic regression are a special form of GAMs.
Welcome back brother !
1) Congrats on becoming a father!! 🥳
2) My favorite NLP newsletter is back!! 😊