
Instruction Tuning Vol. 2

Last month, we covered the first generation of instruction-tuning datasets that have been mainly based on existing NLP tasks.

This month, we cover the latest datasets that are now much closer to real-world use cases—but still have their limitations!
Initiatives to Get Involved in AI Research
Before we get into these, here are a few initiatives to get involved in AI research:
The Aya Project: Help build state-of-the-art multilingual LLMs and make LLMs accessible in your language. Aya launched in January 2023 and is now in the final stage of dataset creation, so now is the time to get involved to make a difference!

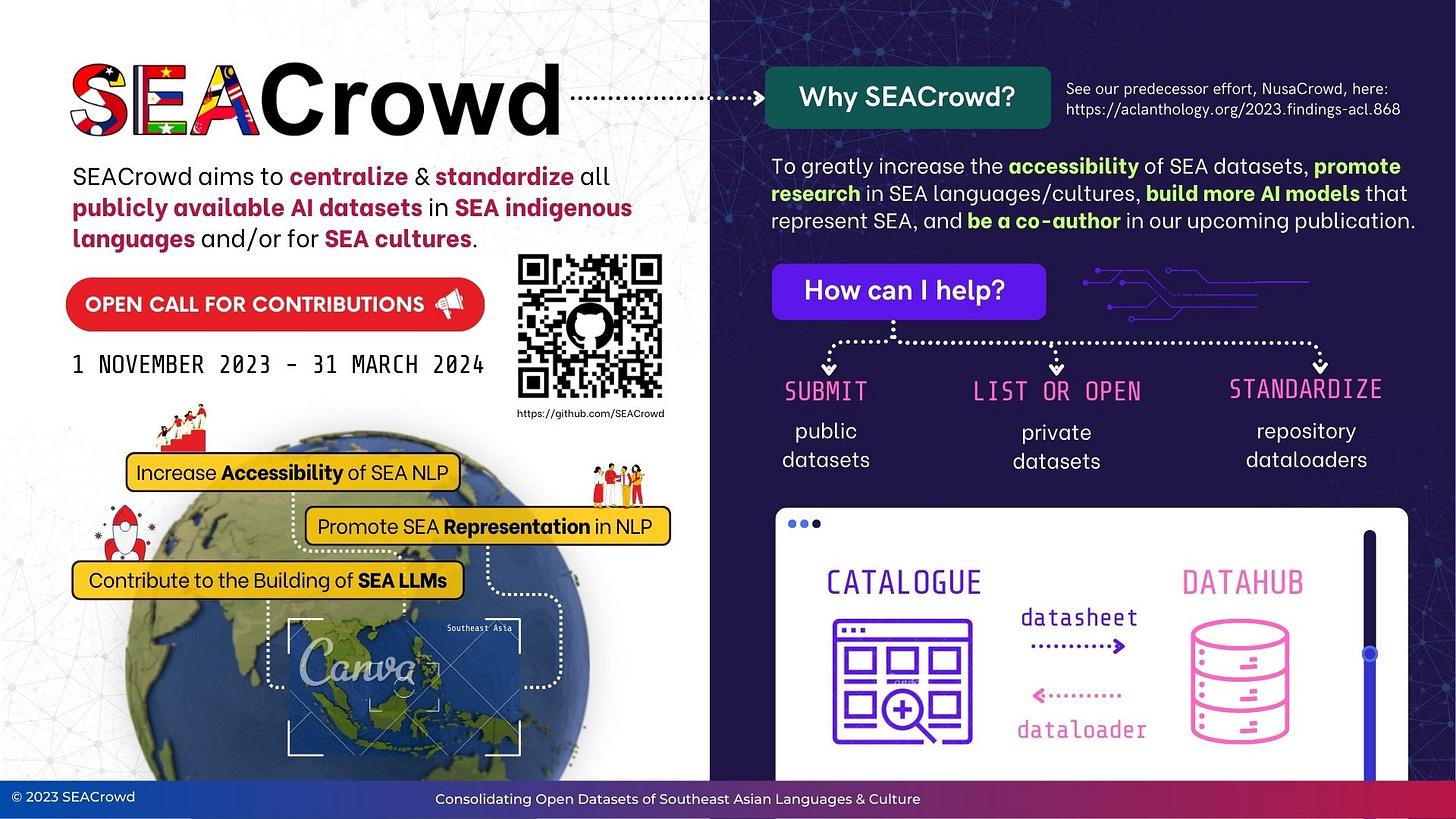
SEACrowd: Make NLP and LLM models more accessible in South-East Asian (SEA) languages by gathering and standardizing SEA datasets. Contributions earn merch 👕 and co-authorship 📝!
Tropical ProbAI: Applications are open for the first Tropical Probabilistic AI School from 29 January – 2 February 2024 in Rio de Janeiro, Brazil. Application deadline is November 24. Tropical ProbAI is also looking for sponsors to help bring AI schools to the under-served Latin American community




Are there any other projects or initiatives that people should be aware of? Let me know.
Characteristics of Instruction-Tuning Data
Now, let’s get on with instruction tuning. There are a few things to consider when using these recent datasets:
Data source: How was the data obtained? Most datasets have been generated using ChatGPT. They may thus inherit biases of the source model or may be noisy. Human-written examples are more expensive to obtain but are more high quality.
Data quality: Was any filtering done to improve the quality of the generated data? In most cases, filtering is based on simple heuristics or a pre-trained model, which can result in noisy data. The authors of OpenAssistant Conversations went the extra mile and obtained human-annotated data quality labels. 💪
Domain and language coverage: Most datasets cover general QA-style use cases and are in English. However, similar methods can be used to obtain data in other domains or languages.
Number of dialog turns: A dialog turn is an utterance by one speaker. Most datasets are single-turn, i.e., they consist of a prompt and a single response. Multi-turn data may be necessary to train a more conversational model.
License terms: Data generated using OpenAI models is subject to the OpenAI terms of use, which prohibit using the data to develop competing models. So look for data with a more permissive license to avoid any legal complications.
The Latest Instruction-Tuning Datasets
Let’s now take a look at the latest generation of instruction-tuning datasets:
Alpaca data (Taori et al., March 2023): 52k English instruction examples generated using OpenAI’s text-davinci-003 with self-instruct (see the previous post for a discussion):
The authors applied some modifications to simplify the data generation pipeline and lower costs—the final data cost less than $500 to generate!
Evol-Instruct (Xu et al., April 2023): A rewritten set of 250k English instruction-response pairs based on the Alpaca data. Instructions are rewritten a) to make them more complex or b) to create a new, more specialized instruction by prompting ChatGPT. In a second step, ChatGPT is used to generate the corresponding responses. Low-quality instruction-response pairs are filtered using heuristics. This process is repeated three times.
Vicuna ShareGPT data (Chiang et al., March 2023): 70k English conversations shared by users and scraped from sharegpt.com. Pre-processing involved converting HTML to markdown, filtering out low-quality samples, and splitting lengthy conversations into smaller segments. Compared to the above single-turn datasets, the ShareGPT conversations often consist of multiple turns and are thus more useful for training a model to leverage the context of the conversation. The conversations may be owned by the users so their use is potentially problematic.
Baize data (Xu et al., April 2023): 54k and 57k English multi-turn dialog examples (3.4 turns on average) generated with ChatGPT using questions from Quora and StackOverflow datasets respectively as seeds. ChatGPT simulates both the human and AI participants of the conversation.1 In addition, they also generated 47k dialogs in the medical domain based on MedQuAD questions.

Multi-turn dialogue data generated using ChatGPT based on a seed from Quora (Xu et al., 2023). databricks-dolly-15k (Conover et al., April 2023): 15k English instruction-following examples written by Databricks employees. Crucially, both instructions and answers are human-generated. This in contrast to the other datasets above where instruction and/or answers are generated by ChatGPT. Examples cover 7 use cases: open QA, closed QA, information extraction and summarization of Wikipedia data, brainstorming, classification, and creative writing. Compared to the other datasets above, the data is released under a permissive license that also allows for commercial use.

An Open QA example in databricks-dolly-15k.OpenAssistant Conversations (Köpf et al., April 2023): 11k crowd-sourced multilingual instruction-following conversations (for 52k examples, only the prompts are available). Human annotators generated messages for both the assistant and the human participant. The data differs in several aspects from the other datasets: 1) it is multilingual (42.8% examples are in English, 31.4% in Spanish, and the rest in other languages); 2) annotators annotated the quality of prompts and responses (460k quality ratings overall); and 3) the annotators were provided with detailed guidelines, both for writing prompts and for acting as the assistant. The data uses a permissive license, which allows commercial use.
LIMA data (Zhou et al., May 2023): 1k training and 300 test answer–response pairs mostly sampled from StackExchange, wikiHow and the Pushshift Reddit dataset with around 400 written by the paper authors. A nice observation of this study is that training on this small set of curated instruction data outperforms training on the much larger, noisier Alpaca data.

Examples from the manually authored portion of the LIMA dataset.



Takeaways
✅ Quality > quantity. As Zhou et al. (2023) observe, training on a small set of high-quality data outperforms instruction-tuning on larger, noisier data. Using more diverse prompts and quality filtering both improve performance.
🧑🎓 Imitation != mastery. Models that are instruction-tuned on ChatGPT-generated data mimic ChatGPT’s style (and may thus fool human raters!) but not its factuality (Gudibande et al., May 2023). They perform worse on standard benchmarks. Using stronger base models is the best way to address this.
🏛️ The stronger the base, the better. More powerful base models also produce stronger instruction-tuned models (Wang et al., June 2023).
🥇 The combination wins. Combining multiple instruction-tuning datasets results in the best average performance across tasks (Wang et al., June 2023). Dataset mixing and developing modular instruction-tuned models are thus important research directions.
Future Directions
Understanding instruction-tuning. While we have seen a proliferation of instruction-tuning datasets, we still lack a clear understanding of what makes a good instruction and good instruction–response pairs. There is much anecdotal knowledge when it comes to creating good model prompts—but to my knowledge it is unclear how instruction–following data can be created at scale in a more principled manner.
Improving data quality. To improve model performance, we need to develop more reliable methods to identify high-quality examples and filter out undesirable ones. In a similar vein, it is important to develop methods that allow us to identify how a particular instance affects model behavior and alignment at test time.
Evaluating instruction-tuned models. In light of the biases of both human and automatic evaluations, there is no clear gold standard for how to evaluate instruction-tuned models. Evaluating a model on a set of tests that can be efficiently and automatically evaluated is one way to side-step this issue, see LMentry (Efrat et al., ACL 2023), M2C (Hlavnova & Ruder, ACL 2023), IFEval (Zhou et al., Nov 2023), etc but these are restricted to a certain set of use cases. In general, it is crucial to design evaluations with a target application in mind.
Are there any exciting developments or directions that I missed? Let me know.
Xu et al. (2023) refer to this setting as ‘self-chat’. This is a continuation of work on machine-to-machine dialogue modeling (see, e.g., Budzianowski et al., 2018) and dialogue self-play (Shah et al., 2018).