
NLP Research in the Era of LLMs
5 Key Research Directions Without Much Compute

Update Dec 30: Added mentions of BabyLM and the Languini Kitchen.
NLP research has undergone a paradigm shift over the last year. A range of large language models (LLMs) has validated the unreasonable effectiveness of scale1. Currently, the state of the art on most benchmarks is held by LLMs that are expensive to fine-tune and prohibitive to pre-train outside of a few industry labs.
In the past, a barrier to doing impactful research has often been a lack of awareness of fruitful research areas and compelling hypotheses to explore2. In contrast, NLP researchers today are faced with a constraint that is much harder to overcome: compute.
In an era where running state-of-the-art models requires a garrison of expensive GPUs, what research is left for academics, PhD students, and newcomers to NLP without such deep pockets? Should they focus on the analysis of black-box models and niche topics ignored by LLM practitioners?
In this newsletter, I first argue why the current state of research is not as bleak—rather the opposite! I will then highlight five research directions that are important for the field and do not require much compute. I take inspiration from the following reviews of research directions in the era of LLMs:
Manning (Dec 2023). Academic NLP research in the Age of LLMs: Nothing but blue skies! EMNLP 2023 Keynote talk, recording (requires EMNLP 2023 registration)
I highly recommend these for different perspectives on current LLM research and for a broader overview of research topics beyond the ones presented in this article.
A Cause for Optimism
Research is cyclical. Computer scientist and ACL lifetime achievement award recipient Karen Spärck Jones wrote in 1994:
Those […] who had been around for a long time, can see old ideas reappearing in new guises […]. But the new costumes are better made, of better materials, as well as more becoming: so research is not so much going round in circles as ascending a spiral.

In the same vein, Saphra et al. (2023) highlight the similarities between the current era of LLMs and the Statistical Machine Translation (SMT) era where translation performance was shown to scale by training a phrase-based language model on more and more web data.
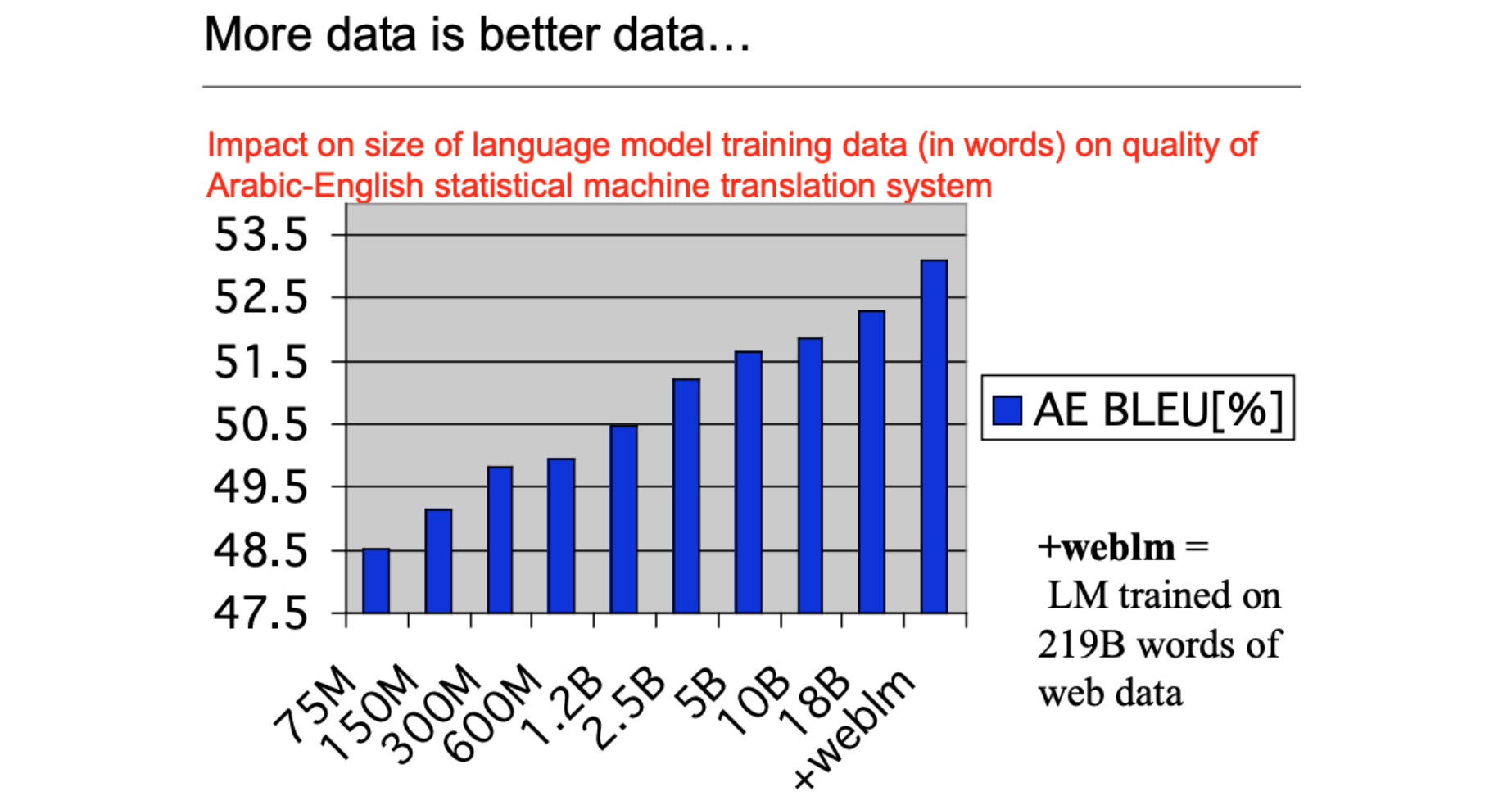
More recently, we have seen the success of scale with the advent of word embeddings in 2013 and the emergence of pre-trained LMs in 2018.3 In all cases, academic research was not left in the dust but went on to make contributions that shaped the next era, from KenLM (Heafield, 2011), an efficient LM library that enabled academics to outperform industry MT systems, to the word2vec alternative GloVe (Pennington et al., 2014), to pre-trained LMs developed in non-profits and academia such as ELMo (Peters et al., 2018) and ULMFiT (Howard & Ruder, 2018).
The main lesson here is that while massive compute often achieves breakthrough results, its usage is often inefficient. Over time, improved hardware, new techniques, and novel insights provide opportunities for dramatic compute reduction.
In his 2018 article, Stephen Merity provides two examples of this trend where the first instance of a method was exorbitantly compute-intensive while only a year later, compute costs were dramatically reduced:
New York Times (2012): "How Many Computers to Identify a Cat? 16,000 (CPU cores)"
One year later: "three servers each with two quad-core CPUs and four Nvidia GeForce GTX 680 GPUs"Neural Architecture Search: "32,400-43,200 GPU hours"
Just over a year later: "single Nvidia GTX 1080Ti GPU, the search for architectures takes less than 16 hours" (1000x less) (paper)
We could argue why the same trend may not be true for this era of LLMs. After all, new techniques can also be scaled up and scale ultimately prevails as we know. In addition, the current trend of closed-source models makes it harder to build on them.
On the other hand, new powerful open-source models are still released regularly4. Companies are also incentivized to invest in the development of smaller models in order to reduce inference cost. Finally, we are starting to see the limits of scale on the horizon: recent LLMs are reaching the limits of text data online and repeating data eventually leads to diminishing returns (Muennighoff et al., 2023) while Moore’s law is approaching its physical limits.
There are already recent examples that require a fraction of compute by using new methods and insights, demonstrating that this trend also holds in the era of LLMs:
FlashAttention (Dao et al., 2022) provides drastic speedups over standard attention through clever hardware optimization.
Parameter-efficient fine-tuning methods (see our EMNLP 2022 tutorial for an overview) including adapters such as LoRA (Hu et al., 2021) and QLoRA (Dettmers et al., 2023) enable fine-tuning LLMs on a single GPU.
Phi-2, a new 2.7B-parameter LLM released last week matches or outperforms models up to 25x its size.
In the near term, the largest models using the most compute will continue to be the most capable. However, there remains a lot of room for innovation by focusing on strong smaller models and on areas where compute requirements will inexorably be eroded by research progress.
While LLM projects typically require an exorbitant amount of resources, it is important to remind ourselves that research does not need to assemble full-fledged massively expensive systems in order to have impact. Chris Manning made the nice analogy in his EMNLP 2023 keynote that in the same vein, aerospace engineering students are not expected to engineer a new airplane during their studies.

With that in mind, let’s look at five important research areas that require less compute.
1. Efficient Methods
Rather than waiting for compute costs to go down, making LLMs more efficient can have a wide impact. When we talk about efficiency, we often think about making the model architecture itself more efficient. In fact, most works on efficient Transformers focused on a specific component, the attention mechanism (Tay et al., 2022).
However, when thinking about efficiency, it is useful to consider the entire LLM stack. Important components ripe for improvement are:
Data collection and preprocessing: improving data efficiency by better filtering and data selection.
Model input: faster, more informed tokenization; better word representations via character-level modeling
Model architecture: better scaling towards long-range sequences; more effective use of memory
Training: more efficient methods to train small-scale LLMs via more effective distillation, better learning rate schedules and restarts, (partial) model compression, model surgery, etc.
Downstream task adaptation: improved parameter-efficient fine-tuning; automatic prompt and chain-of-thought design; modular methods; improved RLHF
Inference: early predictions; prompt compression; human-in-the-loop interactions
Data annotation: model-in-the-loop annotation; automatic arbitration and consolidation of annotations
Evaluation: efficient automatic metrics; efficient benchmarks
Given the wide range of LLM applications, it is increasingly important to consider the ‘human’ part in efficiency: from annotation, to learning from human preferences, to interacting with users, can we make the stages where human and LLM data intersect more efficient and reliable?
Sparsity and low-rank approximations are two general principles that have been applied in a wide range of efficient methods (see our modular deep learning survey for an overview) and are thus useful sources of inspiration: are there components that are modeled with an excess amount of parameters that can be approximated instead? Are there computations involving multiple steps that can be shortened?
In the age of LLMs, the clearest indicator that an efficient method works is that it reduces the coefficient (in other words, lowers the slope) of the corresponding scaling law, as seen for instance in Hoffmann et al. (2022).
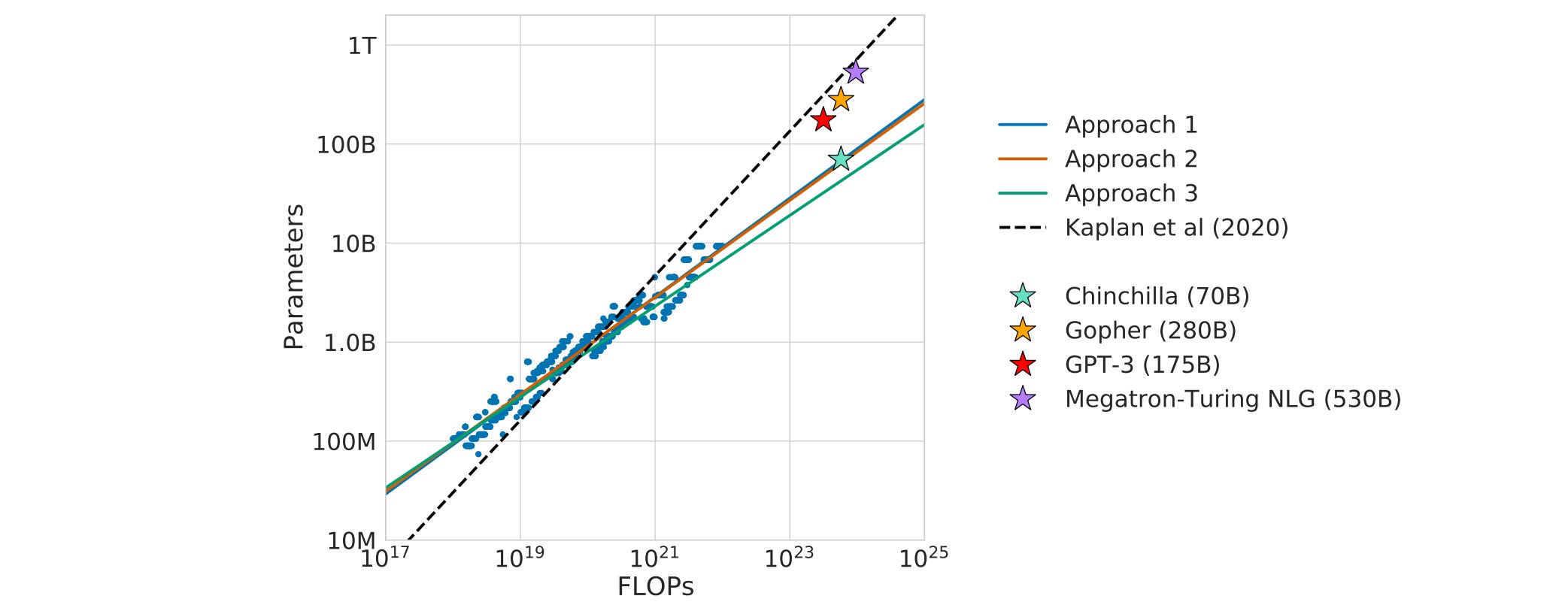
But how can we validate a scaling law without massive compute? By prioritizing experimentation in small-scale regimes.
2. Small-scale Problems
While it is generally prohibitive to apply a new method directly to the largest model, using it on a smaller, representative model can serve as a useful prototype and proof of concept.5 These days in particular, one should not underestimate the pace of the ML and NLP community, which is receptive to and quick-to-adopt compelling new ideas.
For instance, the recently proposed DPO method (Rafailov et al., 2023) used a relatively small-scale experimental setting in the paper (GPT-2-large fine-tuned on IMDb reviews, among others). As the code was open-sourced and compatible with common LLM frameworks, community members quickly applied it to more recent models such as Llama-2 and Zephyr.
Expect to see more of this mode of operation: academic researchers developing new methods that—after small-scale validation—are shared with the community for further experimentation and scaling up.
Methods can also be developed on benchmarks that measure compute and sample efficiency and are designed with compute constraints in mind. Examples include the BabyLM Challenge (Warstadt et al., 2023)—which focuses on sample-efficient pre-training on a developmentally plausible corpus of 10M and 100M tokens—and the Languini Kitchen (Stanić et al., 2023), which compares models based on equivalent compute.
Another setting where a focus on a small scale is increasingly valuable is analysis and model understanding. Through pre-training, models learn a wide array of natural language understanding capabilities—but under exactly what conditions these capabilities emerge remains unclear.
Large-scale pre-training, due to the massive nature of most of the components involved, mostly resists a controlled examination.6 Instead, controlled small and synthetic settings that allow probing of specific hypotheses will be increasingly important to understand how LLMs learn and acquire capabilities. Such settings can include synthetic language such as bigram data (Bietti et al., 2023) or “fake” English (K et al., 2020), highly curated and domain-specific data, and data satisfying certain (distributional) characteristics; as well as more interpretable models such as small Transformers, backpack language models (Hewitt et al., 2023), and neural additive models (Agarwal et al., 2021).
LLM mechanisms whose emergence is still poorly understood include the following:
in-context learning: ‘burstiness’ and the highly skewed distribution of language data are important (Chan et al., 2022) but the in-context learning ability can also disappear again during training (Singh et al., 2023)
chain-of-thought prompting: local structure in the training data is important (Prystawski et al., 2023) but we don’t know how this relates to natural language data
cross-lingual generalization: limited parameters, shared special tokens, shared position embeddings, and a common masking strategy contribute to multilinguality (Artetxe et al., 2019; Dufter & Schütze, 2020) but it is unclear how this extends to diverse natural language data and typologically diverse languages
other types of emerging abilities (see for instance Schaeffer et al., 2023)
Rather than trying to make large-scale settings smaller to reduce the amount of compute necessary to study them, we can also focus on settings that are intrinsically small-scale due to constraints on the data available.
3. Data-constrained Settings
While the largest LLMs are pre-trained on trillions of tokens, the downstream applications we would like to apply them to are often more limited in the data available to them.
This is true for many interdisciplinary areas such as NLP for Science, Education, Law, and Medicine. In many of these domains, there is very little high-quality data easily accessible online. LLMs thus must be combined with domain-specific strategies to achieve the biggest impact. See Li et al. (2023) for a brief review of directions in NLP+X applications.
Another area where data is notoriously limited is multilinguality. For many languages, the amount of text data online is limited—but data may be available in other formats such as lexicons, undigitized books, podcasts, and videos. This requires new strategies to collect—and create—high-quality data. Furthermore, many languages and dialects are more commonly spoken than written, which makes multi-modal models important to serve such languages.
As we reach the limits of data available online, even “high-resource” languages will face data constraints. New research will need to engage with these constraints rather than assuming an infinite-scale setting.
While few-shot prompting enables seamless application to many downstream tasks, it is insufficient to teach a model about the nuances of more complex applications and is limited in other ways. Alternatively, parameter-efficient fine-tuning enables a more holistic adaptation using little compute. Such fine-tuning—when updates are constrained to a subset of model parameters—gives rise to modular models.
Given the diversity of LLM application areas and capabilities to master, another interesting direction is thus to leverage multiple modular ‘experts’ by learning to disentangle and combine the skills and knowledge learned across different domains.
Such modeling advances, however, are of little use if we do not have reliable means to evaluate them.
4. Evaluation
"[...] benchmarks shape a field, for better or worse. Good benchmarks are in alignment with real applications, but bad benchmarks are not, forcing engineers to choose between making changes that help end users or making changes that only help with marketing."—David A. Patterson; foreword to Systems Benchmarking (2020)
In 2021, a common sentiment was that NLP models had outpaced the benchmarks to test for them. I reviewed the situation in this article; not much has changed since then. More recent benchmarks designed to evaluate LLMs such as HELM (Liang et al., 2022) and Super-NaturalInstructions (Wang et al., 2022) still mainly consist of standard NLP tasks—most of them sentence-level—while others such as MMLU (Hendrycks et al., 2021) and AGIEval (Zhong et al., 2023) focus on exams. These benchmarks do not reflect the diverse range of tasks where we would like to apply LLMs.
Another phenomenon to be aware of is leaderboard contamination: benchmark data that is available online is likely to have been included in the pre-training data of LLMs, making evaluation unreliable. Benchmarks should thus keep evaluation data secret or receive regular updates.
"When you can measure what you are speaking of and express it in numbers, you know that on which you are discussing. But when you cannot measure it and express it in numbers, your knowledge is of a very meagre and unsatisfactory kind."—Lord Kelvin
In addition, existing automatic metrics are ill-suited for more complex downstream applications and open-ended natural language generation tasks. LLMs can be incorporated into automatic metrics (Liu et al., 2023) but one must be aware of—and mitigate—their biases. For complex tasks, it may be useful to decompose them into subtasks that are easier to evaluate, for instance, via behavioral tests (Hlavnova & Ruder, 2023).
As applications become more elaborate, even human evaluation, traditionally perceived to be the gold standard for any data, becomes less reliable. Disagreements may be less an indicator of ‘annotation noise’ and rather a sign of different perspectives (Pavlick & Kwiatkowski, 2019). For specialized applications, only domain experts may be qualified enough to provide accurate feedback. Leveraging and aggregating the feedback of a diverse set of annotators from different backgrounds is thus more important than ever.
5. Reasoning
Reasoning requires the use of logic to draw conclusions from new and existing information to arrive at a conclusion. With LLMs demonstrating surprising arithmetic and logical reasoning abilities, reasoning has received renewed attention and was well-represented in NeurIPS 2023 papers (see my previous newsletter):
Given that LLMs frequently hallucinate and struggle to generate code or plans that are directly executable, augmenting them with external tools or small domain-specific models is a promising direction to make them more robust. For instance, Parsel (Zelikman et al., 2023) decomposes a code generation tasks into LLM-generated subfunctions that can be tested against input-output constraints using a code execution module.
Many complex real-world applications require different forms of reasoning so evaluating models’ reasoning abilities in realistic scenarios is an important challenge. Given that many real-world problems require weighing different options and preferences, it will be crucial to enable LLMs to present different solutions to users and to incorporate different cultural backgrounds into their decision-making. Ignat et al. (2023) highlight other interesting research directions related to reasoning.
This post presented a selection of five research directions that are particularly important in my opinion—but in truth there are a plethora of potential opportunities to explore (see the other reviews at the beginning of this post). Now is the time to look beyond standard NLP tasks and be ambitious. After all:
“Shoot for the moon. Even if you miss, you'll land among the stars.”
—Norman Vincent Peale
Also known as Rich Sutton’s bitter lesson, in other words, “the great power of general purpose methods, of methods that continue to scale with increased computation even as the available computation becomes very great”.
I shared ‘requests for research’ in 2018 where each task required a few GPUs at most for training a neural network from scratch.
For an overview of NLP milestones until 2018, check out my “Review of the Neural History of NLP”.
Hugging Face referred to 2023 as the year of open LLMs.
For example, we recently trained mmT5 (Pfeiffer et al., 2023), a modular version of multilingual T5 that dramatically outperforms its counterpart at small and base parameter sizes, demonstrating the benefits of modularity at this scale.
Nevertheless, certain areas such as memorization can be studied during large-scale pre-training by modifying the pre-training scheme appropriately, for instance via the insertion of ‘canaries’ as in PaLM 2 (Anil et al., 2023).
Hi Regan,
Sure. Feel free to translate the post to Chinese and share it with proper attribution.
Hey Sebastian, great read and very interesting points! Do you know if Chris Manning's EMNLP 2023 keynote is available anywhere another than on the conference's site?