
Pre-training + Massive Multi-tasking, Benchmarking in NLP, EMNLP primer, 🤗 NLP Course, ACL 2021 recap,

Hi all,
First off, some personal news: I've moved from DeepMind to Google Research this week. Because of this move, the past months have been quite busy. In light of this, I decided to pause the newsletter over the last couple of months. I plan to continue with it in a more sustainable manner.
I'll be continuing to work on multilingual NLP, with a focus on under-represented languages, particularly those in Sub-Saharan Africa. On this note, if you are thinking of doing research in this area, I can't think of a better thing to do than apply for a funding opportunity via the Lacuna Fund. The call this time includes a mentorship program in collaboration with the amazing people from Masakhane.
I really appreciate your feedback, so let me know what you love ❤️ and hate 💔 about this edition. Simply hit reply on the issue.
Click here to view the newsletter in your browser.
If you were referred by a friend, click here to subscribe. If you enjoyed this issue, give it a tweet 🐦.
Pre-training + Massive Multi-tasking 💑
Multi-task learning (MTL), training a model on several tasks at once and sharing information is a general method that is fundamental to training neural networks. Rich Caruana's 1997 paper is one of the best introductions to this topic and as relevant today as it was back then. For more recent overviews, you can check out my survey from 2017 or a survey from 2020 that I enjoyed.
Research in multi-task learning has long shown that models trained on many tasks learn representations that generalize better to new ones. A common problem in multi-task learning, however, is minimizing negative transfer, i.e. how to make sure that tasks that are dissimilar do not hurt each other.
In recent years despite much work on alternative training objectives, the NLP community has gravitated to a single pre-training objective to rule them all, masked language modelling (MLM). Much recent work has focused on ways to adapt and improve it (e.g., Levine et al., 2021). Even the next-sentence-prediction objective used in BERT has become slowly phased out (Aroca-Ouellette & Rudzicz, 2020).
Recently, there has been a flurry of papers that show not only that multi-task learning helps pre-trained models, but that gains are larger when more tasks are used. Such massive multi-task learning settings cover up to around 100 tasks, going beyond earlier work that covered around 50 tasks (Aghajanyan et al., 2021).
A key reason for this convergence of papers is that multi-task learning is much easier with recent models, even across many tasks. This is due to the fact that many recent models such as T5 and GPT-3 use a text-to-text format. Gone are the days of hand-engineered task-specific loss functions for multi-task learning. Instead, each task only needs to be expressed in a suitable text-to-text format and models will be able to learn from it, without any changes to the underlying model.
The newly proposed approaches differ in terms of how and when multi-task learning is applied. One choice is fine-tuning an existing pre-trained model on a collection of multiple tasks, i.e. behavioural fine-tuning. This is done by T0 (Sanh et al., 2021), one of the first outcomes of the BigScience workshop, using T5 and FLAN (Wei et al., 2021) using a GPT-3-like pre-trained model. Both papers describe a unified template and instruction format into which they convert existing datasets. BigScience open-sources their collection of prompts here. Both papers report large improvements in terms of zero-shot and few-shot performance compared to state-of-the-art models like T5 and GPT-3.
Min et al. (2021) propose a different fine-tuning setting that optimizes for in-context learning: instead of fine-tuning a model on examples of a task directly, they provide the concatenation of k+1 examples to a model as input x_1, y_1, ..., x_k, y_k, x_{k+1} and train the model to predict the label of the k+1-th example, y_{k+1}. They similarly report improvements in zero-shot transfer.
In contrast to the previous approaches, ExT5 (Anonymous et al., 2021) pre-trains a model on a large collection of tasks. They observe that using multiple tasks during pre-training is better than during fine-tuning and that multi-task pre-training combined with MLM is significantly more sample-efficient than just using MLM (see below).

On the whole, these papers highlight the benefit of combining self-supervised pre-training with supervised multi-task learning. While multi-task fine-tuned models were always somewhat inferior to single-task models on small task collections such as GLUE—with a few exceptions (Liu et al., 2019; Clark et al., 2019)—multi-task models may soon hold state-of-the-art results on many benchmarks. Given the availability and open-source nature of datasets in a unified format, we can imagine a virtuous cycle where newly created high-quality datasets are used to train more powerful models on increasingly diverse task collections, which could then be used in-the-loop to create more challenging datasets.
In light of the increasingly multi-task nature of such models, what then does it mean to do zero-shot learning? In current training setups, datasets from certain tasks such as NLI are excluded from training in order to ensure a fair zero-shot scenario at test time. As open-source multi-task models trained on many existing tasks become more common, it will be increasingly difficult to guarantee a setting where a model has not seen examples of a similar task. In this context, few-shot learning or the full supervised setting may become the preferred evaluation paradigms.
Benchmarking in NLP 🥇

Many talks and papers at ACL 2021 made reference to the current state of NLP benchmarking, which has seen existing benchmarks largely outpaced by rapidly improving pre-trained models, in spite of such models still being far away from true human-level natural language understanding.
My favourite resources on this topic from the conference were:
Chris Pott's keynote on Reliable characterizations of NLP systems as a social responsibility.
Rada Mihalcea's presidential address where she emphasises evaluation beyond accuracy.
Samuel Bowman's and George Dahl's position paper asking "What Will it Take to Fix Benchmarking in Natural Language Understanding?"
I've also written a longer blog post that provides a broader overview of different perspectives, challenges, and potential solutions to improve benchmarking in NLP.
EMNLP 2021 primer 🏝
EMNLP papers are now available in the ACL anthology. I'll be attending the conference virtually. I'm particularly looking forward to the virtual poster sessions (as these feel closest to an in-person conference experience).
In terms of the conference program, I was particularly excited to see Visually Grounded Reasoning across Languages and Cultures (Liu et al., 2021) being awarded the Best paper award. The paper highlights biases in the concepts and images in ImageNet and proposes a new multilingual dataset for Multicultural Reasoning over Vision and Language (MaRVL; see below for examples). We need more work that creates such high-quality datasets in a culturally diverse setting.

If this is your first time at a conference, I would recommend you to prioritize meeting and connecting with people. Approach others and introduce yourself (whether in-person or at the virtual GatherTown). Go to posters, both those which are well-attended and those where only the presenter is present; the latter often make for a more insightful and stimulating discussion. Above all else, have fun (we all need it after the last two years). If you are presenting something at the conference or just want to say hi, feel free to send me a message.
You can also find me doing the following things during the conference:
November 9: presenting a poster (poster session link) and talk (oral session link) for XTREME-R (paper link)
November 10: presenting a keynote on multilingual evaluation at the Eval4NLP workshop (conference link, external link)
November 11: co-presenting a hybrid tutorial on Multi-Domain Multilingual Question Answering (conference session link; slides link) as well as co-hosting The 1st Workshop on Multi-lingual Representation Learning (conference link; external link)
Also check out the following EMNLP 2021 together with collaborators:
IndoNLG: Benchmark and Resources for Evaluating Indonesian Natural Language Generation: The first benchmark (and new models) for NLG in Indonesian.
UNKs Everywhere: Adapting Multilingual Language Models to New Scripts: New methods + a system evaluation to adapt pre-trained models to unseen scripts.
Efficient Test Time Adapter Ensembling for Low-resource Language Varieties (Findings): A simple ensembling-based method to use existing language adapters for adapting to unseen languages and language varieties.
MAD-G: Multilingual Adapter Generation for Efficient Cross-Lingual Transfer (Findings): A method based on hyper-networks to generate language adapters for cross-lingual transfer.
Upcoming NLP course by Hugging Face 🤗
One thing that is great about doing NLP these days is that there are a lot of resources to help you get started as well as a lot of tooling and infrastructure to work easily with state-of-the-art models.
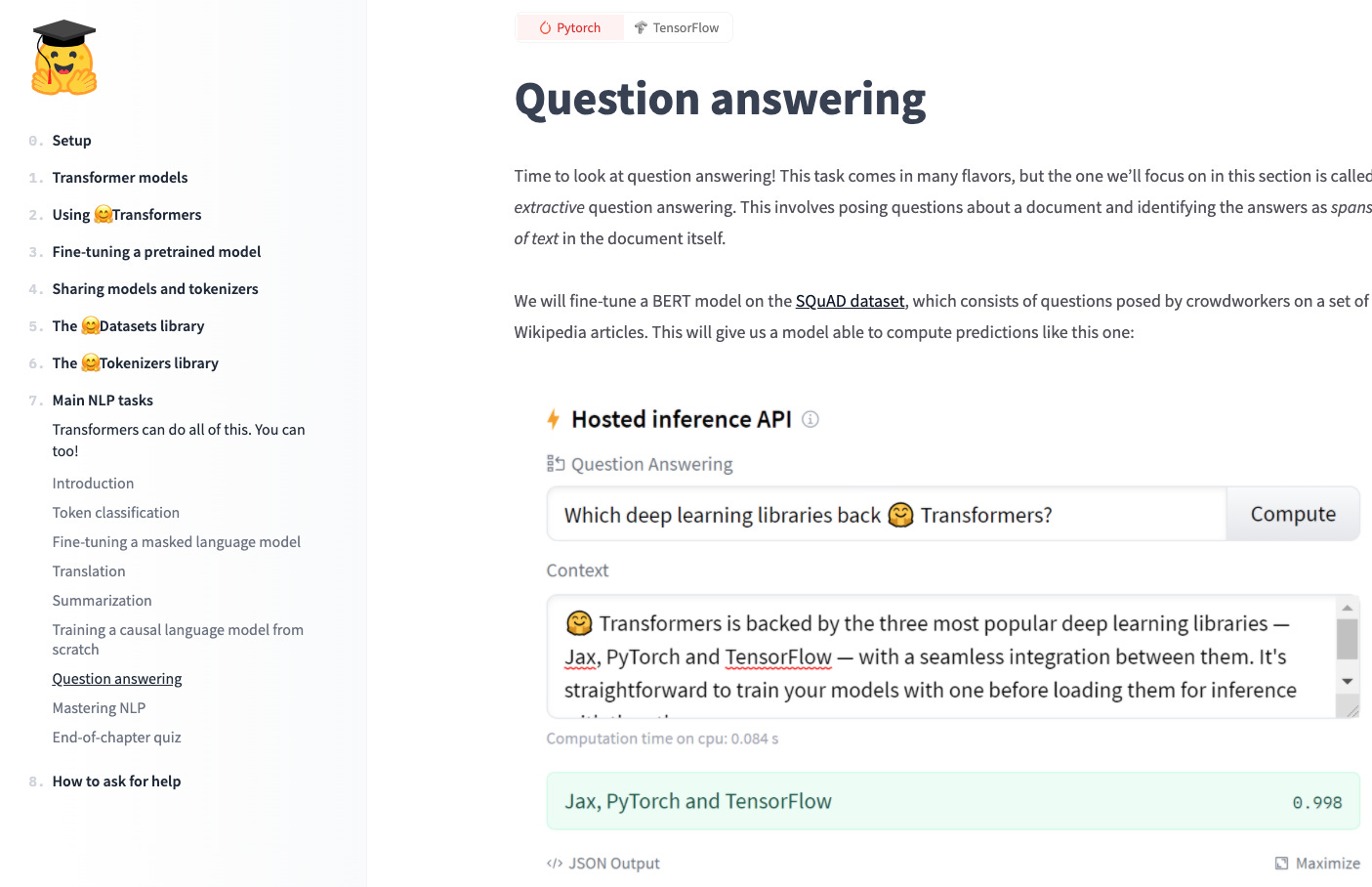
A nice resource for learning about using NLP is the NLP course by Hugging Face. Four chapters are currently available, with more to be released by November 16. The new chapters discuss how to create datasets and tokenizers as well as how to deal with many standard NLP settings, such as fine-tuning a model for translation, summarization, or question answering (see below).
ACL 2021 recap 🏛

This should come as no surprise but it's still interesting to see that among the 14 "hot" topics of 2021 (see above) were 5 pre-trained models (BERT, RoBERTa, BART, GPT-2, XLM-R) and 1 general "Language models" topic. These models are essentially all variants of the same Transformer architecture. This serves as a useful reminder that the community may be overfitting to a particular setting and that it may be worthwhile to look beyond the standard Transformer model (see my recent newsletter for some inspiration).
It seems everyone is exhausted by virtual conferences at this point as I wasn't able to find any write-ups of people's highlights of ACL 2021, in contrast to past conferences (I also didn't manage to finish mine).
If you're attending EMNLP 2021, I hope you'll share your highlights, experience, and insights with the community.